Kluges That Work: Turning Pattern Matchers into Logical Reasoners

In his book “Kluge: The Haphazard Construction of the Human Mind,” Gary Marcus details how our brains have been shaped by evolution into a structure that is functional but imperfect. According to Marcus, the human brain is a “kluge,” a clumsy or inelegant - yet surprisingly effective - solution to the problem of guiding a human body.
How did the human brain become such a kluge? The answer lies in the incremental nature of evolution. As Richard Dawkins described in “Climbing Mount Improbable,” evolution progresses gradually, like climbing a mountain. Evolution builds on what already exists by making small improvements and selecting the "best" option at each stage. While a more optimal solution may exist hypothetically, evolution is constrained to adapt to what is currently available. It climbs peaks one step at a time.
Today, Marcus, a professor of psychology at New York University, has emerged as one of the most prominent critics of artificial intelligence and large language models. Along with thinkers like Noam Chomsky, Marcus has articulated the significant limitations of LLMs and argued for caution in their unfettered development.
Marcus points out that LLMs rely entirely on detecting patterns in huge datasets, not true understanding. As a result, they cannot reason or comprehend ideas meaningfully. LLMs simply regurgitate information based on what they have been trained on.
Yet something curious is unfolding. Researchers, engineers, and hobbyists are experimenting with LLMs to solve increasingly complex problems that should, in theory, outstrip their capabilities. Each week, new papers announce incremental improvements to get more out of LLMs, tweaking mechanisms and discarding those that fail.
In evolution, natural selection pits organisms against the environment to determine which adaptations succeed. In AI, researchers use benchmarks to evaluate which approaches perform well enough to continue pursuing.
HumanEval: Can your LLM code?
One such benchmark is Human Eval. First introduced in a paper titled "Evaluating Large Language Models Trained on Code" (2021) by Open AI, it checks for the functional correctness of programs generated by LLMs.
HumanEval measures the models on a pass metric. A pass@1 score indicates the likelihood of a model generating the correct solution on one try. A pass@100 score measures the likelihood of generating at least one correct solution after 100 attempts.
OpenAI’s Codex, a model tailored for code generation, achieved a pass@1 score of 33.5% and a pass@100 score of 77.4% on the HumanEval benchmark besting GPT-3, which had a pass@1 score of 0! In other words, Codex had a one in three chance of generating the right solution on one try but a three in four chance of getting it right within 100 tries. The challenge is determining which of the 100 attempts is correct.
i.e. generative AI generates a lot of BS.
Scarecrow: "I haven't got a brain… only straw."
Dorothy: "How can you talk if you haven't got a brain?"
Scarecrow: "I don't know. But some people without brains do an awful lot of talking, don't they?"
One way to make sure you have the right code is to test it.
CodeT: Testing your way to the right answer
In software engineering, test-driven development (TDD) is a practice where engineers first write tests before writing a single line of code. However, writing effective tests is difficult and laborious. In 2022, researchers at Microsoft proposed a method called CodeT that uses language models to generate test cases and code samples automatically.
Now the tests could tell us which code output is the right one. But, the LLM could generate incorrect tests that pass faulty code samples. To address this, CodeT applies “dual execution agreement,” meaning code must not only pass the tests but produce outputs that match other code samples. On the HumanEval benchmark, CodeT achieved a pass@1 score of 65.8%, indicating it can generate a valid solution and set of tests on the first attempt nearly two-thirds of the time.
But this is brute force. Researchers began to wonder if they could emulate how humans solve problems.
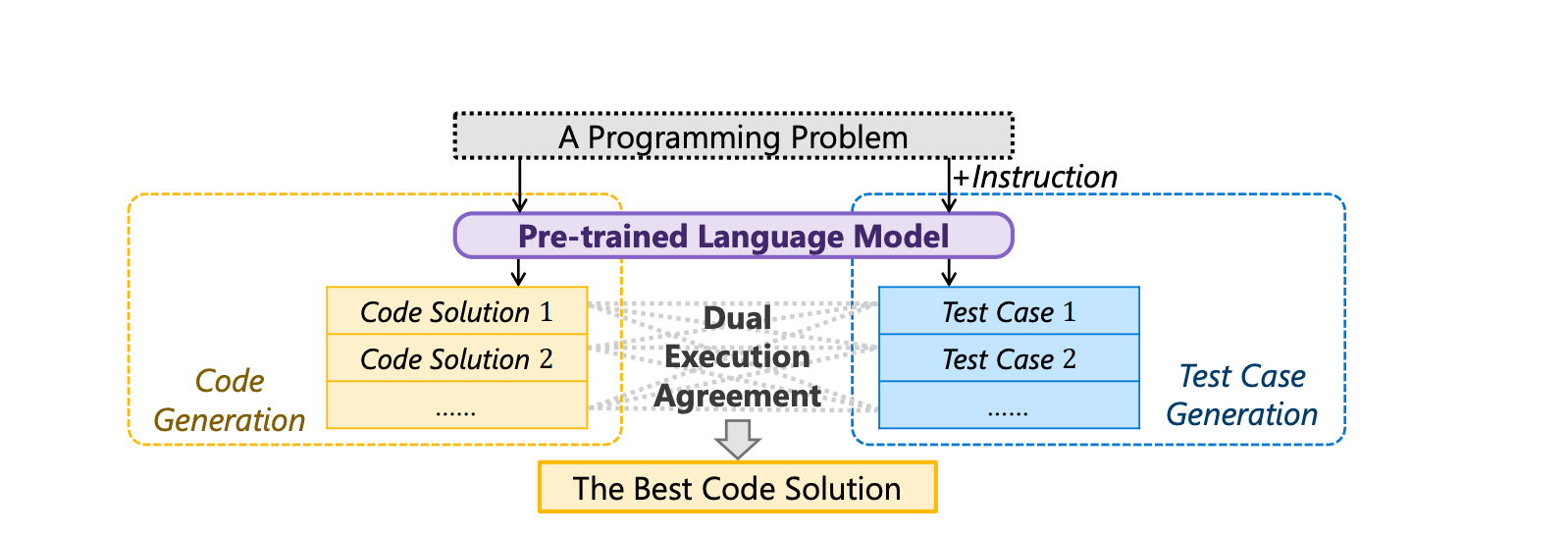
Dual execution agreement from CodeT
Parsel: Think in an intermediate language
Large language models (LLMs) are complex algorithms that predict the sequence of words most likely to follow a given prompt. At their core, they are sophisticated text completion engines. True reasoning, on the other hand, usually requires breaking down problems into steps.
Researchers are finding ways to push LLMs beyond mere text completion and into simulacra of reasoning. For example, scientists at Google and the University of Tokyo discovered that prompting LLMs to “think in steps” can enhance their performance on certain reasoning tasks. In their paper “Large Language Models are Zero-Shot Reasoners,” they showed that adding the phrase "think in steps" to prompts improved models’ reasoning abilities. The chain-of-thought prompting technique builds on this by giving models examples of step-by-step thinking.
Stanford researchers Eric Zelikman and colleagues leveraged these insights to create Parsel, a framework for training LLMs to decompose complex problems into a series of steps. Given a task, an LLM generates a “Parsel program” representing the steps to solve it. The program is translated into code and tested against constraints to find the correct solution.
Using Parsel, the pass@1 accuracy rate increased to 85%.

The parsel pipeline
Reflexion: Thinking about thinking
Humans have a powerful ability to reason by reflecting on their own thinking, known as metacognition. This skill allows people to learn and create more efficiently. What if we could teach AI systems this same ability to self-reflect?
Recent studies have explored this possibility. The paper “Self-Refine: Iterative Refinement with Self-Feedback” trained language models to review and improve their initial responses. The model was given its own output and asked to provide feedback on how to enhance it. This feedback was then incorporated into the next iteration, where the model refined its response based on the feedback. Remarkably, the models improved without any additional data or training.
A similar framework called “Reflexion: Language Agents with Verbal Reinforcement Learning” enabled AI agents to self-reflect and evaluate their performance. Reflexion agents reviewed task feedback, recorded their reflections in memory, and used these to make better decisions in the future. Reflexion incorporated various types of feedback, from simple ratings to complex language responses.
Reflexion+GPT-4 has a pass@1 of 91%.
You are an advanced reasoning agent that can improve based on self refection. You will be given a previous reasoning trial in which you were given access to relevant context and a question to answer. You were unsuccessful in answering the question either because you guessed the wrong answer with Finish or there is a phrasing discrepancy with your provided answer and the answer key. In a few sentences, Diagnose a possible reason for failure or phrasing discrepancy and devise a new, concise, high level plan that aims to mitigate the same failure. Use complete sentences.
Prompt used in Reflexion.
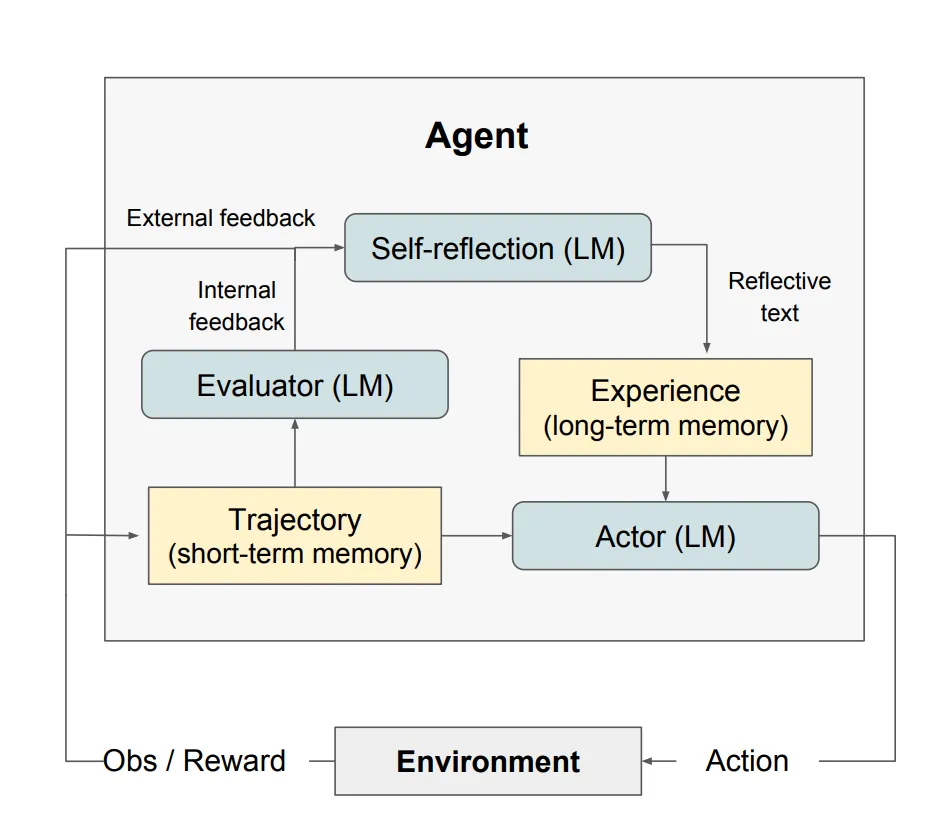
The agent feedback look in Reflexion
Kluges That Work: The Serendipity of AI Evolution
We have come a long way since 2021 when GPT-3 could not generate a single correct program (pass@1 score of 0). Today, improved models and prompting techniques have enabled pass@1 scores of over 90% on benchmark tasks. Yet LLMs remain, at their core, simply probabilistic engines completing tokens based on patterns, lacking internal knowledge representations or mechanisms for logical reasoning.
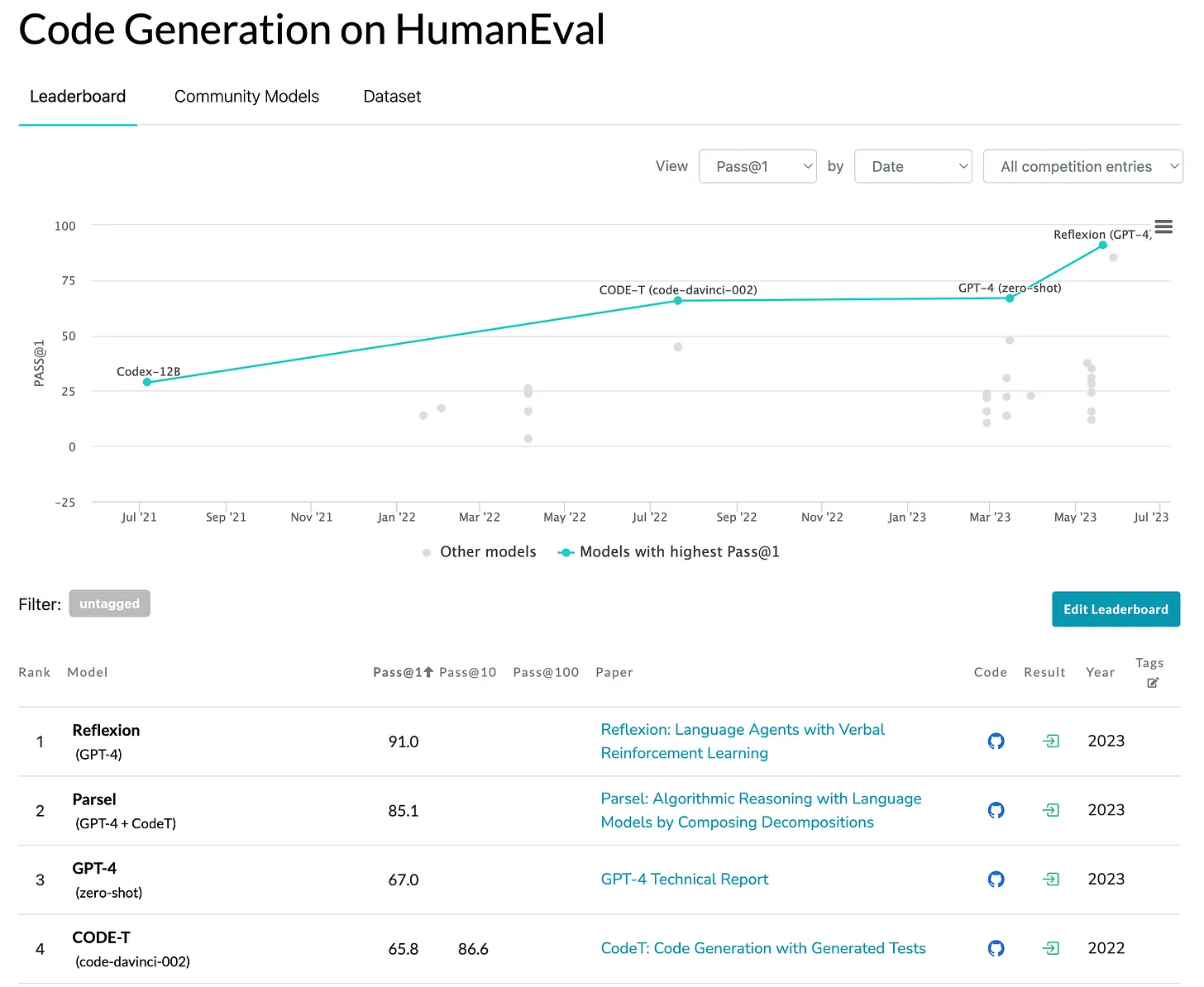
HumanEval Leaderboard on Paperswithcode.com
This progress has been driven not by elegant, rational design but by the inexhaustible enthusiasm of researchers for tinkering, experimenting, and making incremental improvements to systems at hand—just as evolution slowly shapes and selects for changes that work. Most attempts end in dead ends, but a rare few point the way forward. It is a winding, haphazard path, but one that continues moving in a direction of greater capability, complexity and competence over time. In the end, the reasoning systems built on LLMS might be inelegant —a kluge—and yet if it works, that might be all that matters.
Want these insights delivered? Subscribe below.